深層学習の数理にて:自由確率論とランダムDNN, AISTATS2021採択論文解説
AISTATS2021に採択された論文"The Spectrum of Fisher Information of Deep Networks Achieving Dynamical Isometry"について, 数学部分の解説をします.
序論: 論文の概略
深層学習の数理
今回の研究は, 深層回路はどんなに深いネットワークでも学習できるのか?という疑問と関連する話です. 近年, 様々な研究によって, 深層回路の理論・数理が探求されてきました. その重要なテーマとして、表現能力, 学習可能性, 汎化性能がありますが, 今回の研究は学習可能性に分類できます. 特に, 層数が増えていったときの, 学習ダイナミクスの変化を調べます.
勾配消失発散とDynamical Isometry
学習可能なネットワークに絞るため, 勾配消失発散が起きないDNNを対象とします. DNNは大抵確率的勾配降下法(SGD)で学習されます. DNNの勾配は, 微分の連鎖律から各層の勾配行列の積になります. 従って, パラメータの初期値や活性化関数のナイーブな設定の下では, 層数が増えるごとに指数的に勾配が消失・発散し学習できなくなってしまうのです. 勾配消失発散を防ぐため, 以下の性質が調べられてきました (Saxe et. al., 2014, Pennignton et al., 2018, Xial et al., 2018, Sokol and Park 2020):
- Edge of Chaos: 層を跨いで勾配の二乗平均が保たれる.
- Dynamical Isometry: DNNの入力に関するJacobianの特異値が層数増加に対し定数オーダー. Dynamical Isometry はEdge of Chaosよりも強い性質です. また, Pennignton et al., 2018では, MLP(Multilayer Perceptron, DNNの中で最も基礎的なもの)がDynamical Isometryを満たすためには, ガウス初期化ではなく直交初期化(と活性化関数の正規化)を使えばよいことが分かりました. 今回の研究では, MLPと直交初期化を使います.
- 参考: 10000-layer CNN (without ResNet, BatchNorm)をDynmaical Isometryで学習: Xiao et. al.,2018
DNNの学習ダイナミクスとFisher情報行列
Dynamical Isometry下でDNNの学習ダイナミクスはどのようになっているでしょう?今回は, ロス空間の(局所的な)計量を決めるDNNのFisher情報行列を調べます.
貢献
今回の研究では自由確率論という数学を用いて, いくつかのことが分かりました. 最も重要なものは以下の結果です.
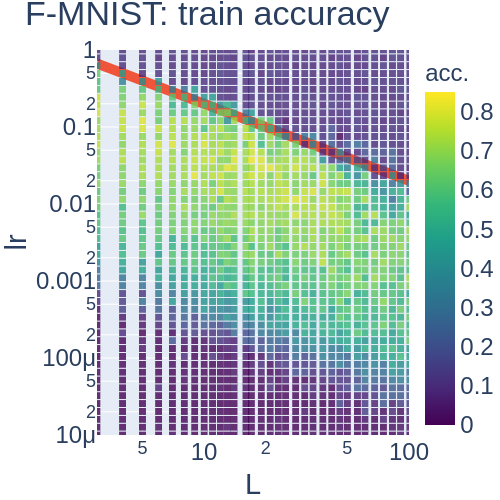
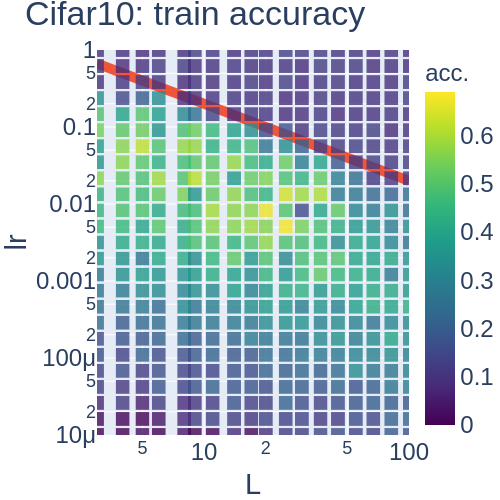
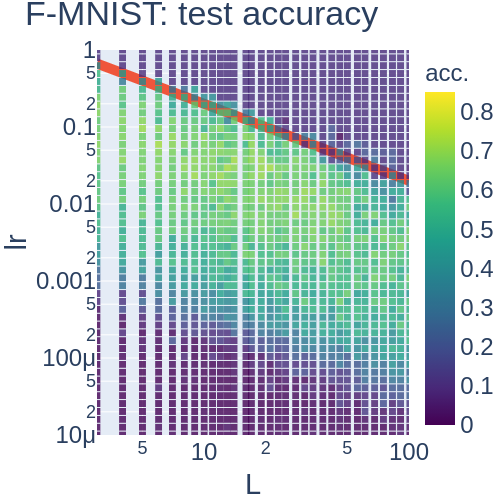
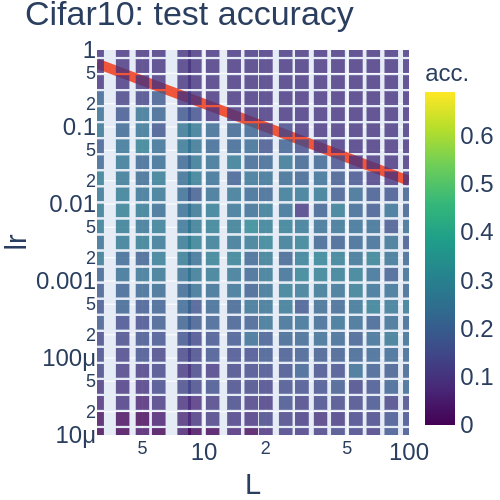
- MLPがDynamical Isometryを満たすとき, サンプルごとのFisher情報行列の(ゼロ以外の)固有値は, 最大固有値に集中する. 最大固有値は層数に比例する (Hayase and Karakida 2021, Theorem 4.3). ここで, 最大固有値が層数に応じて増えるのは想像に難くありませんが, 最大固有値に集中することは非自明です. このことから, 学習率は層数に反比例して設定すればよいということが推論できます. また, 実験の結果とピッタリ合っています (Fig. 2). 強調すべきは, Dynamical Isometry下ではJacobianの特異値は層数に依存しないのに, Fisher情報行列は層数に依存するという点です.
本編
紹介した論文で用いた数理の解説をできるだけ流れがわかりやすく説明します.
DNNの設定
MLPを考えます:
MSE-Lossを考えたとき, サンプル毎のFisher情報行列は以下の行列と同じ固有値を持ちます(自明なゼロ固有値を除く).
この時, 以下の漸化式が成り立ちます.
ここで, をの成分の二乗平均で, はJacobianです.
ランダム行列と自由確率論
さて, 今回初期化時点でのDNNを考えるので, 行列はランダム行列の多項式となっています. ランダム行列の多項式の固有値を調べるとき, 自由確率論(Dan V. Voiculescu)が便利です. この節で自由確率論の紹介をします.
自由確率論はバーチャルな確率論のひとつです. ここで, ”バーチャルな確率論”は本質的には確率論であること, もしくは確率論のエッセンスであるという意味で使っています. 本質というのは絶対的なものではなく, 目的に応じて抽出されたエッセンスです. バーチャルな確率論は確率論のすべての性質を持っていなくてもいいし, 目的に応じて重要な性質を持っていれば十分です.
自由確率論の目的と, 確率論から抽出する対象は以下の通りです.
- 目的: ランダム行列の多項式の固有値解析(本来は, この固有値解析を作用素環の自由積の解析に使うため. 今回は関係が薄いので略)
- 抽出する概念: 確率変数とその代数演算(和・積), 確率空間, 確率分布, 期待値, モーメント, 独立性, 分布収束. この中で基盤となるのは確率変数の代数演算です. 自由確率論は確率論の代数的性質を抽出しています. それでは順に, それぞれの概念をどのように抽出するか見ていきましょう.
確率空間/変数/分布
まず, 通常の確率空間, 確率変数と確率分布の定式化を復習します. 確率空間とは, 3つ組のことで, ここでは集合, は上の-加法族, は可測空間()上の確率測度です. (はイベントの集まりで, 確率事象を細かく決めたい場合要素が増えます. ) 確率変数とは, 確率空間上の実数値Borel可測関数です. 確率変数の確率分布は上の確率測度です.
ここで確率変数が変数と呼ばれる理由について少し説明します. 確率論において, 与えられた確率変数の確率分布を求めるのは基本的な問題です. ここで確率分布はすべての有界連続関数に対して
となる確率測度として特徴づけられます . ここでは期待値です. この式を見ると, 確率変数はの変数になっています. この式を使って確率分布を計算するとすることが頻繁にあります. (特性関数・フーリエ変換もこの類です). その時, 確率変数は上の可測関数というより, 付加する関数の変数としての役割が中心になるのです.
から代数的な性質を抽出して, 確率変数・期待値・モーメント・独立性などの概念とそれに関連する結果(中心極限定理など)を固有値解析に流用します.
議論
おまけの結果として, 層数が浅い場合に, Fisher情報行列(サンプル毎)の特異値分布を(幅無限の極限で)陽に書くことができました (Figure 3).
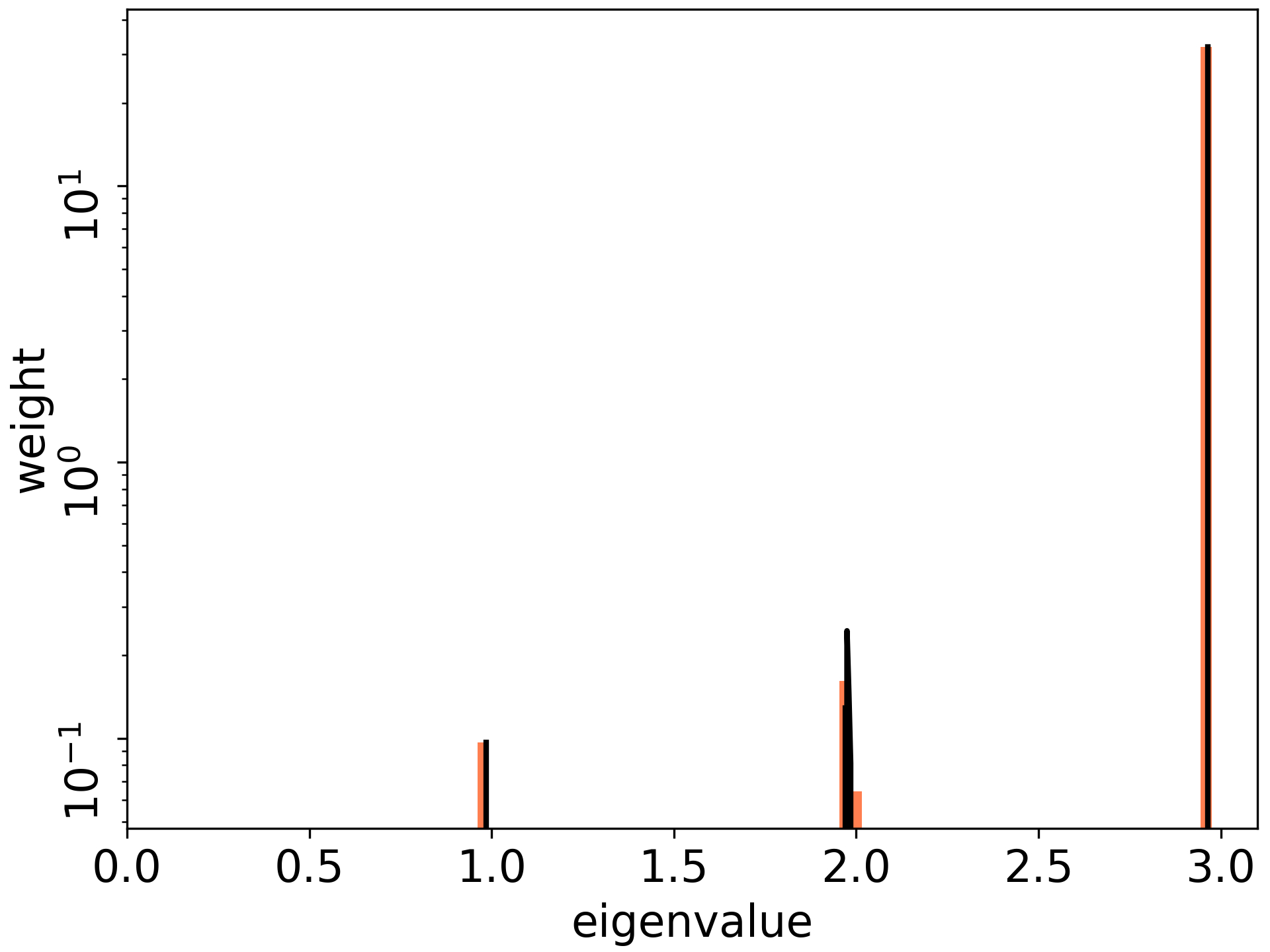
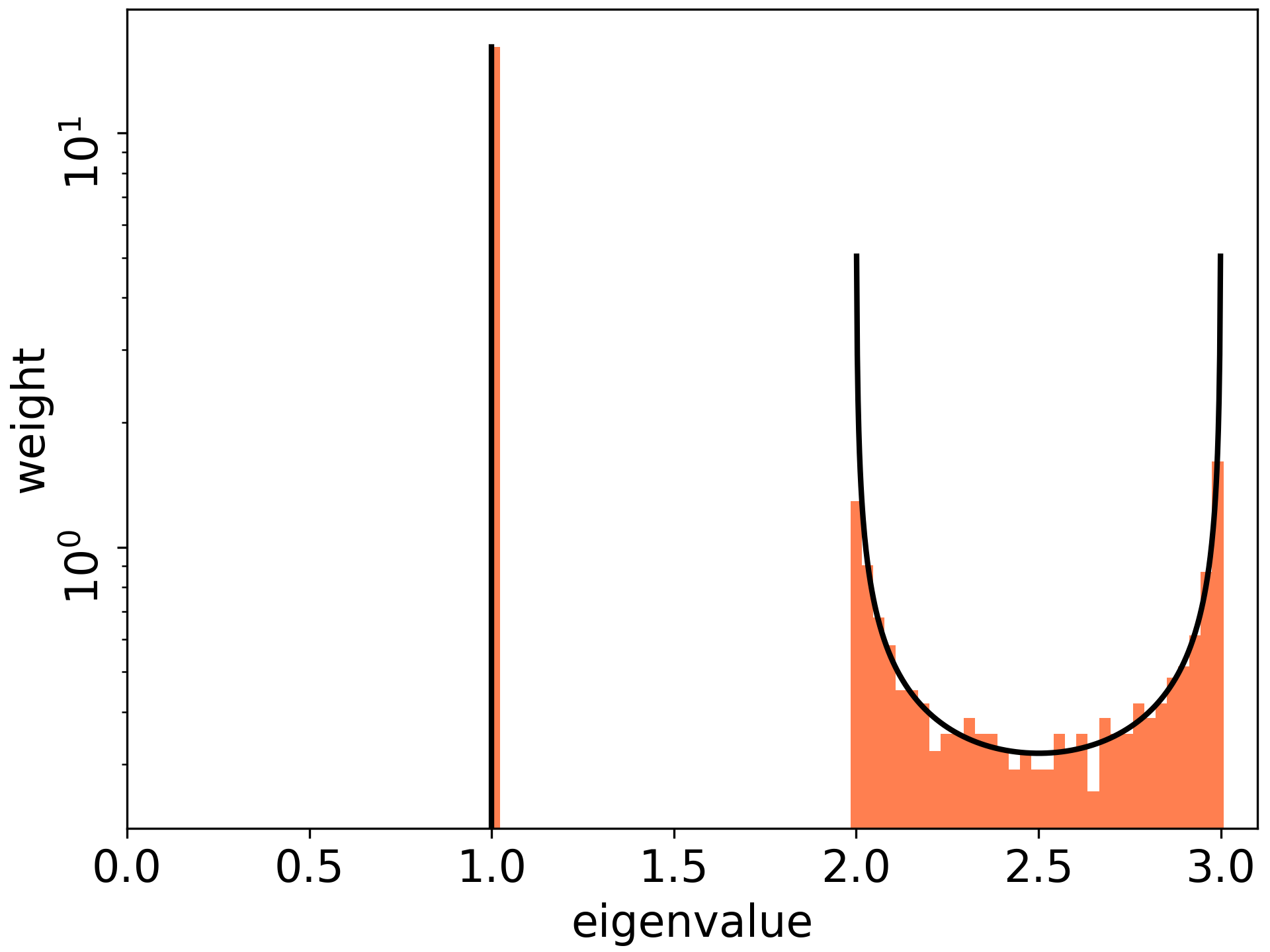
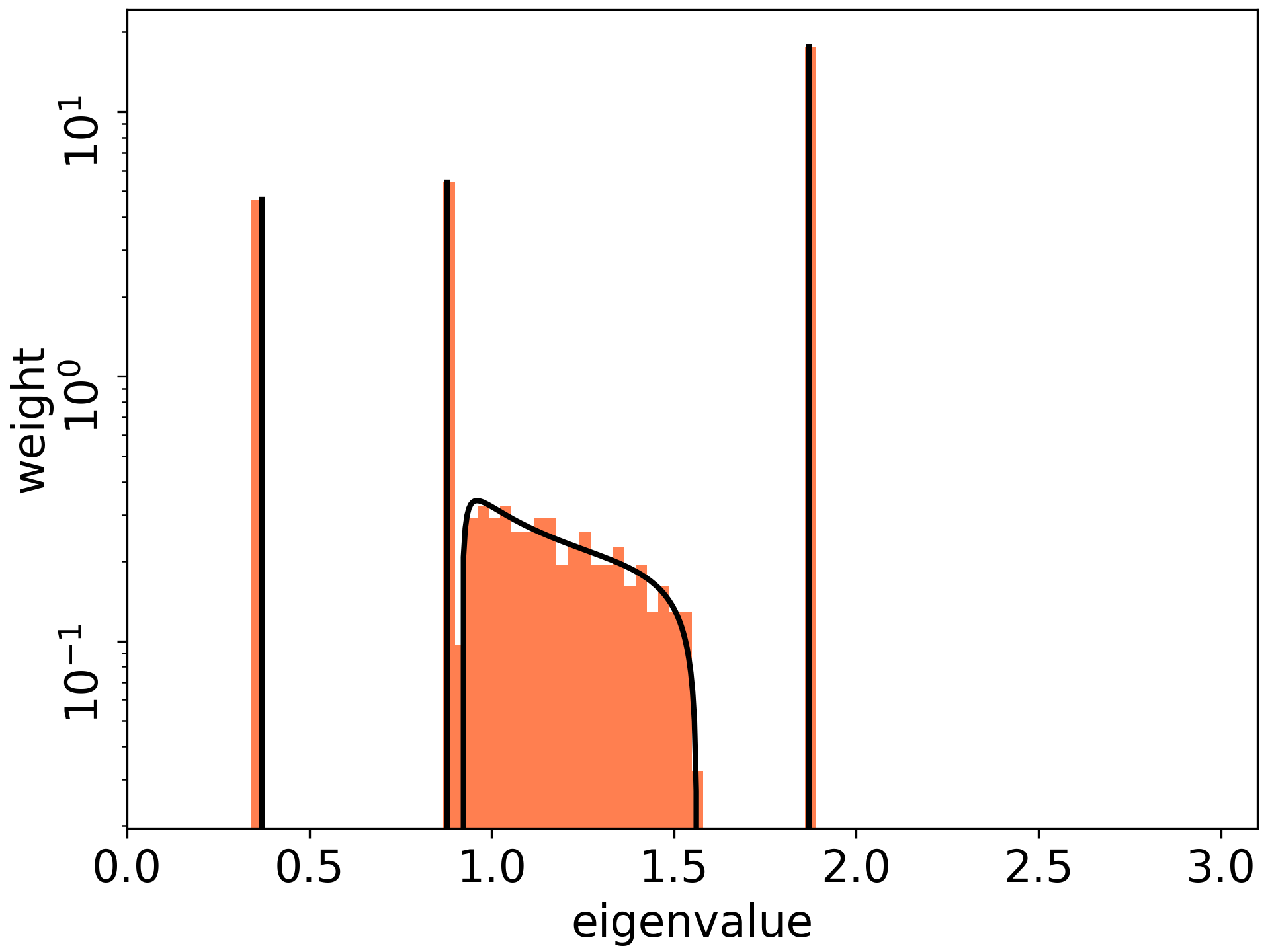
Figure 3. 特異値分布の理論値(黒線)と実験値 (オレンジのヒストグラム)がぴったりと合致している. 一番左がDynamical Isometryの設定. このとき最大固有値( これは層数3に等しい)に多くの固有値が集まっていることが分かる.
また, 後続の論文(Benoit, Hayase, 2021)にて, 理論において重要だが明らかではなかった仮定(漸近的自由独立性)を示すことができました. サンプル数を増やした際の分布は今後追求する必要がああります.
おわりに
DNNの学習ダイナミクスの解析において, しばしばランダムネットワークの設定が使われることがあります. これは学習初期の様子が分かるという点も大事ですが, それだけではありません. 実は適切な設定(NTK-regime (Jacot et al. 2018) ) のもとで学習ダイナミクスが初期化時点で分かるということが知られています. 他にもある程度のそのパラメーター一つ一つではなくてパラメーターの統計性に注目していると言うこともできます. まとめると, ある程度DNNの性質を定性的に大雑把に知りたいとき, 特に幅や深さが大きくなっていく漸近的な挙動を知りたいという場合, ランダムネットワークを調べることは有効です.
参考文献
Benoit Collins, Tomohiro Hayase, "Asymptotic Freeness of Layerwise Jacobians Caused by Invariance of Multilayer Perceptron: The Haar Orthogonal Case"
Tomohiro Hayase, Ryo Karakida, "The Spectrum of Fisher Information of Deep Networks Achieving Dynamical Isometry"
Ryo Karakida, Shotaro Akaho, and Shun-ichi Amari. Universal statistics of Fisher information in deep
neural networks: Mean field approach. In Proceedings of International Conference on Artificial Intelligence and Statistics (AISTATS), 1032-1041, 2019
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in neural information processing systems (NeurIPS), pages 8571–8580, 2018.
Jeffrey Pennington, Samuel Schoenholz, and Surya Ganguli. The emergence of spectral universality in deep networks. In Proceedings of International Conference on Artificial Intelligence and Statistics
(AISTATS), pages 1924–1932, 2018.
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. ICLR 2014, arXiv:1312.6120, 2014.
Lechao Xiao, Yasaman Bahri, Jascha Sohl-Dickstein, Samuel S Schoenholz, and Jeffrey Pennington. Dynamical isometry and a mean field theory of CNNs: How to train 10,000-layer vanilla convolutional neural networks. In Proceedings of International Conference on Machine Learning (ICML), pages 5393–5402, 2018.