Understanding MLP-Mixer as a wide and sparse MLP through random permutation matrix
Understanding MLP-Mixer as wide and sparse MLP through Random Permutation Matices
Tomohiro Hayase
Talk at
Non-Commutative Probability Theory, Random Matrix Theory and their Applications(NPRM2023)
2023/11/08--09
 Preprint:
Preprint:
Table of Contents
- Effective Expression of MLP-Mixer
- Preliminaries
- Symmirarity between MLP and MLP-Mixer
- Effective Width
- Monarch Matrices
- Alternative to static sparse weight MLP
- Random Permuted Mixers
- Revisit the similarity in wider cases
- Conclusion and Future Works
1. Effective Expression of MLP-Mixer
Introduction
Research Question: Why MLP-Mixer has higher performance than usual MLP? Our Answer: Because layers in MLP-Mixer are extremely wide MLP.
Preliminaries
MLP
MLP (multilayer-perceptron) is a composition of transforms in the form of
where is a parameter matrix ( the transforms do not share the parameter matrices).
Static Mask: Consider a matrix of entries 0 or 1 and replace W by M \odot W:
MLP-Mixer
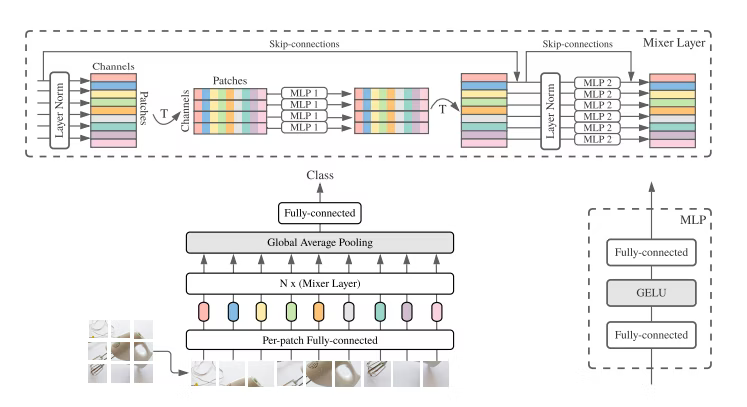 NeurIPS2021, Tolstikhin, et.al
NeurIPS2021, Tolstikhin, et.al
The structure is less structured than Convolutional Neural Networks or Vision Transformers.
Blocks of MLP-Mixer:
where , , , .
Symmirarity between MLP-Mixer and MLP via vectorization
Vectorization and effective width
We represent the vectorization operation of the matrix matrix by ; more precisely,
In other words, the map is the representation
We also define an inverse operation to recover the matrix representation.
There exists a well-known equation for the vectorization operation and the tensor ( or Kronecker) product denoted by ;
for and .
As discussed later, the aforementioned equation corresponds to the vectorization of an MLP-Mixer block with a linear activation function.
The vectorization of the feature matrix is equivalent to a fully connected layer of width
with a weight matrix . We refer to this as the *effective width *of mixing layers.
Under vectorization of feature matrices
Channel-Mixing layer is converted into :
Token-Mixing layer is converted into:
In MLP-Mixer, when we treat each feature matrix as an -dimensional vector , the right multiplication by an weight and the left weight multiplication by a weight are represented as \begin{align}
This expression clarifies that the mixing layers work as an MLP with special weight matrices with the tensor product. As usual,
Mixer is equivalent to an extremely wide MLP
Moreover, the ratio of non-zero entries in the weight matrix is and that of is .
e.g. Block-matrix rep:
Therefore, the weight of the effective MLP is highly sparse.
Commutation Matrix
Furthermore, to consider only the left multiplication of weights, we introduce commutation matrices:
A commutation matrix is defined as
where is an matrix. Note that for nay entry-wise function ,
Note that
Effective Expression of MLP-Mixer: Channel-MLP Block:
Token-MLP Block:
MLP with static-mask
Static Mask: Consider a matrix of entries 0 or 1 distributed and replace W in each layer of MLP by :
- The mask matrix is fixed durring the trainining.
Hidden features and test accuracy
To validate the similarity of networks in a robust and scalable way, we look at the similarity of hidden features of MLPs with sparse weights and MLP-Mixers based on the centered kernel alignment (CKA) Nguyen T., Raghu M, Kornblith S.
In practice, we computed the mini-batch CKA [Section~3.1(2)](Ngueyen 2021) among features of trained networks.
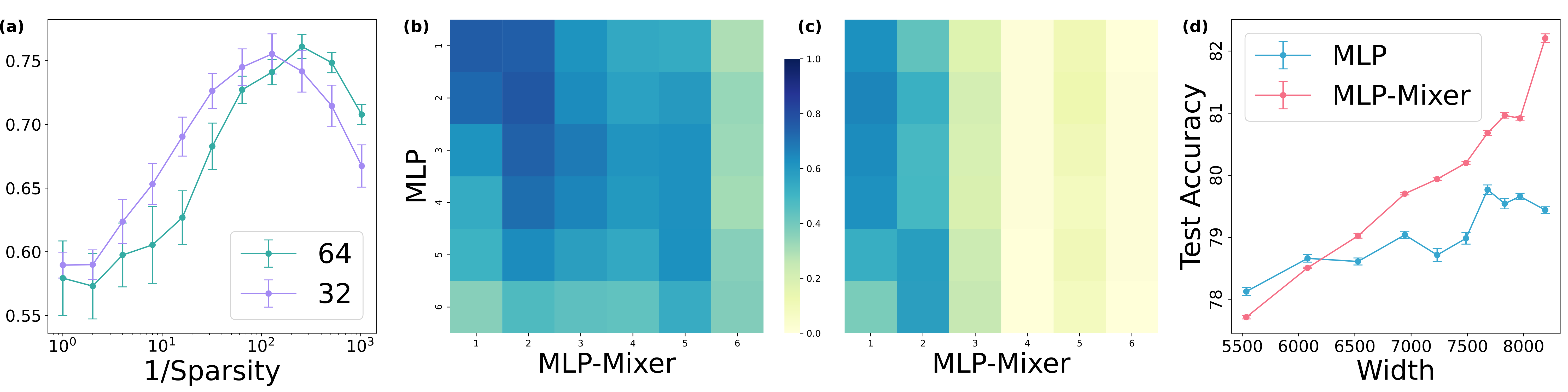
Each experiment is done on CIFAR10with four random seeds. (a) Average of diagonal entries of CKA between trained MLP-Mixer () and MLP with static mask with different sparsity (= ratio of 1 in entries of masks). Sparser MLP was similar to (b) CKA between MLP-Mixer () and MLP with the corresponding sparsity , and (c) CKA between the Mixer and a dense MLP. (d) Test accuracy of MLPs with sparse weights and MLP-Mixers with different widths under .
2. Alternative to MLP with static masks
The comparison in larger scales
Random Permuted Mixer
Since the MLP with static mask requires much memory, it is hard to compare it with MLP-Mixer on larger images (such as ImageNet) than CIFAR10.
We introduce Random-Permuted (RP) Mixer by replacingwith random permutation matrices in the following way:
where and are independent uniformly distributed permutation matrix.
Note that
- RP-Mixer is less structured than MLP-Mixer: RP-Mixer does not share tokens.
- RP-Mixer is more algebraically structured than MLP with random static masks:
Similarity of MLP-Mixer and RP-Mixer: Tendency on S and C
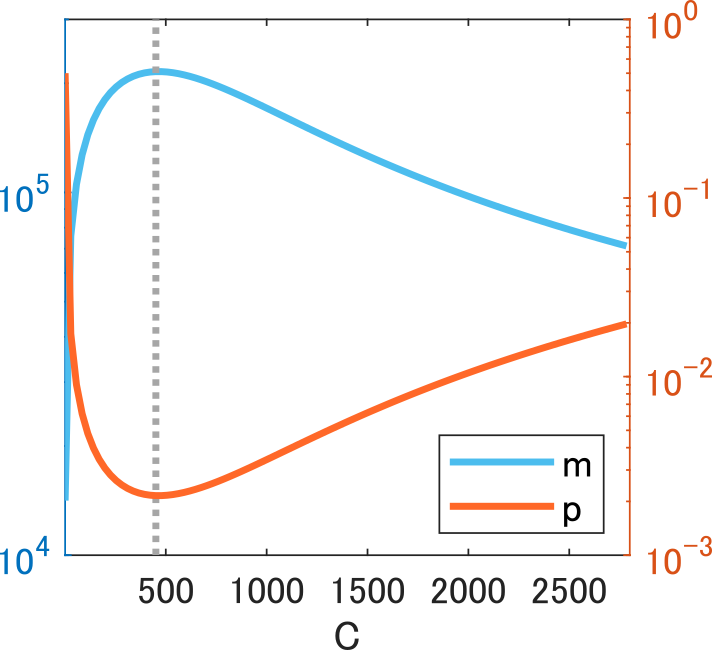
the max is achieved when with
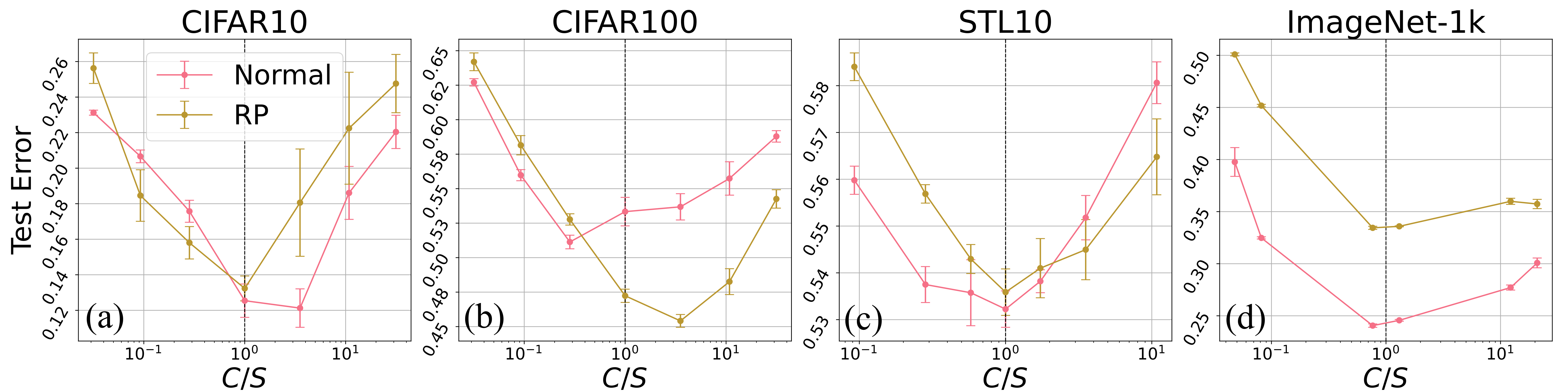 Mixers achieved highest test accuracy around C=S.
Mixers achieved highest test accuracy around C=S.
Application to HPS : An increase in the width fixed number of connections
To validate the similarity, we compare the classification error of both networks with different sparsity. Under the fixed number of connectivity, the sparsity is equivalent to the wideness.
The following hypothesis has a fundamental role:
Hypothesis(Golubeva et. al (2021)) An increase in the width while maintaining a fixed number of weight parameters leads to an improvement in test accuracy.
The average number of non-zero entries per layer :
By widening , the test accuracy imporoved. In addition,

Test Accuracy imporved by chosing to widen the layers:
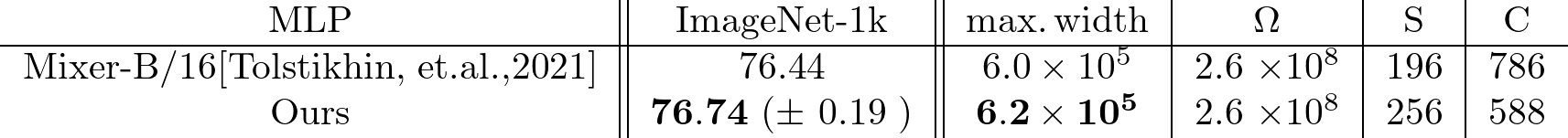
The Monarch matrix is a non-activation version.
Dao, et. al 2022 proposed a monarch matrix:
where and are the trainable block diagonal matrices, each with blocks of size . The previous work claimed that the Monarch matrix is sparse in that the number of trainable parameters is much smaller than in a dense matrix. Despite this sparsity, by replacing the dense matrix with a Monarch matrix, it was found that various architectures can achieve almost comparable performance while succeeding in shortening the training time. Furthermore, the product of a few Monarch matrices can represent many commonly used structured matrices such as convolutions and Fourier transformations.