Random Matrices, Free Probability, and Deep Neural Networks
Random Matrices, Free probability, and Deep Neural Networks
Tomohiro Hayase,
Cluster Metaverse Lab, Japan.
Talk at Workshop: Bridges between Machine Learning and Quantum Information Science (CIRM)
2024/9/09-10
 and T.H. and Benoit Collins, “Asymptotic freeness of layerwise Jacobians caused by invariance of multilayer perceptron”, in Comm. In Math. Phys. (2023), https://link.springer.com/article/10.1007/s00220-022-04441-7.
and T.H. and Benoit Collins, “Asymptotic freeness of layerwise Jacobians caused by invariance of multilayer perceptron”, in Comm. In Math. Phys. (2023), https://link.springer.com/article/10.1007/s00220-022-04441-7.
Based on T.H and Ryo Karakida, “Understanding MLP-Mixer as a Wide and Sparse MLP”, in ICML2024,
Table of Contents
Overview
Deep neural network and Gaussian processJacobian
Stability of DNN and random matricesNTK
Training dynamics and random matricesAsymptotic Freeness Main theorem: asymptotic freeness of Jacobians
MLP-Mixer
- Preliminaries
- Symmirarity between MLP and MLP-Mixer
- Effective Width
- Monarch Matrices
Alternative to static sparse weight MLP
- Random Permuted Mixers
- Revisit the similarity in wider cases
Summary and Future Work
1.Overview
Multilayer Perceptron
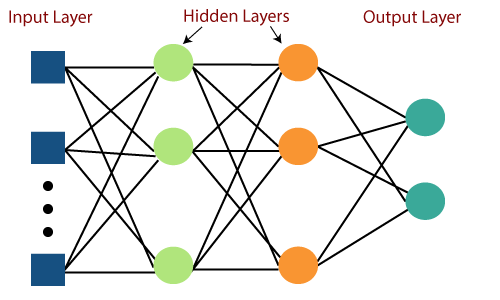 [Figure: https://www.javatpoint.com/multi-layer-perceptron-in-tensorflow]
Let
Parameters:
[Figure: https://www.javatpoint.com/multi-layer-perceptron-in-tensorflow]
Let
Parameters:
Forward propagation: for set and inductively
Finally, define the output by
: Activation Function
Deep Learning
Generally, a standard formulation of supervised deep learning is as follows:
- We are given a finite set of pairs of input/output data .
- We are given a deep neural network (DNN), which is a composition of (parameterized) transformations that maps a real vector to a real vector.
- We are given an object function: e.g. mean squared loss
Optimization
We minimize the loss function by gradient descent:
Initialization of Parameters and Random Matrices
e.g. Gaussian (Ginibre) random matrix:
e.g. Haar distributed orthogonal matrix:
The Infinite-dimensional Limit is Gaussian
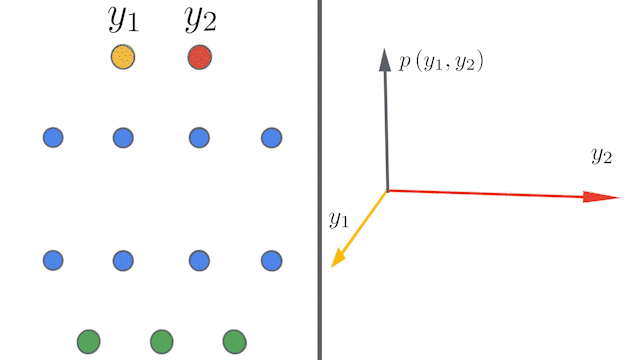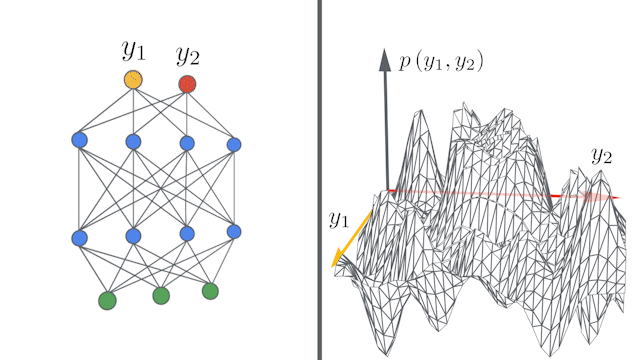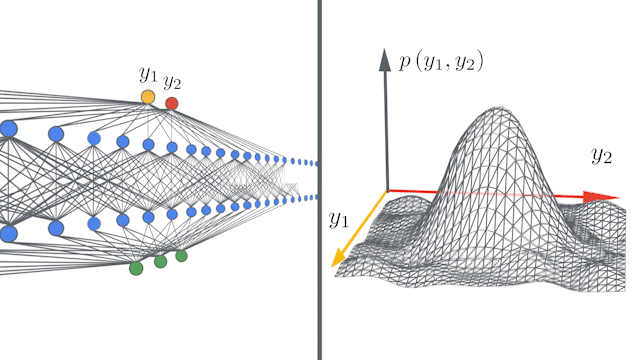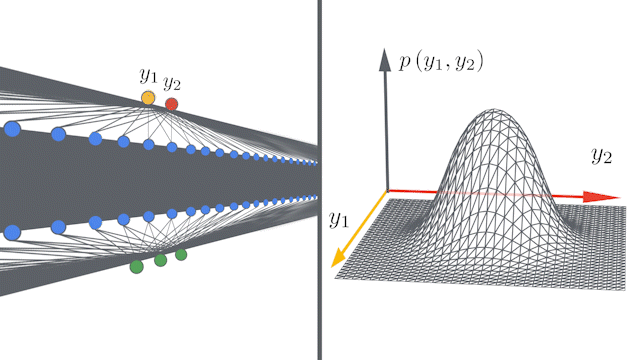 [Figure: https://ai.googleblog.com/2020/03/fast-and-easy-infinitely-wide-networks.html]
[Figure: https://ai.googleblog.com/2020/03/fast-and-easy-infinitely-wide-networks.html]
Neural Network Gaussian Process (NNGP)
Consider two inputs and corresponding hidden units and in MLP. Taking an infinite dimensional limit at the initial state, we have [Lee+ICLR2018]
where
We have the following Kernel Propagation:
where
- For some activation functions, we can compute the integral explicitly.
Application: NNGP Estimation
Generally, consider samples. Set be input/output samples.
Then the posterior mean/ var is given by the following: for a new input
[Lee et.al., Deep Neural Networks as Gaussian Process, ICLR 2018]
2.Jacobian
Vanishing/Exploding Gradients
The optimization of DNN needs its parameter derivations. Since a DNN is a function composition, the chain rule computes the parameter derivations. The input-output Jacobian is defined as
In the case of MLP, we have
where
Dynamical Isometry
A DNN is said to achieve dynamical isometry If the eigenvalue distribution is concentrated around one. Dynamical Isotmetry prevents the exploding/vanishing gradients.
[Pennington+, AISTATS2018, CH, CIMP2022] If we set the initialization of parameters to be Haar orthogonal and choose the appropriate activation function, then we can make the DNN to achieve the dynamical isometry.
Set be limit spectral distributions of as wide limits respectively.
Under the assumption of the asymptotic freeness of Jacobians,
where is the free multiplicative convolution,
Distribution of
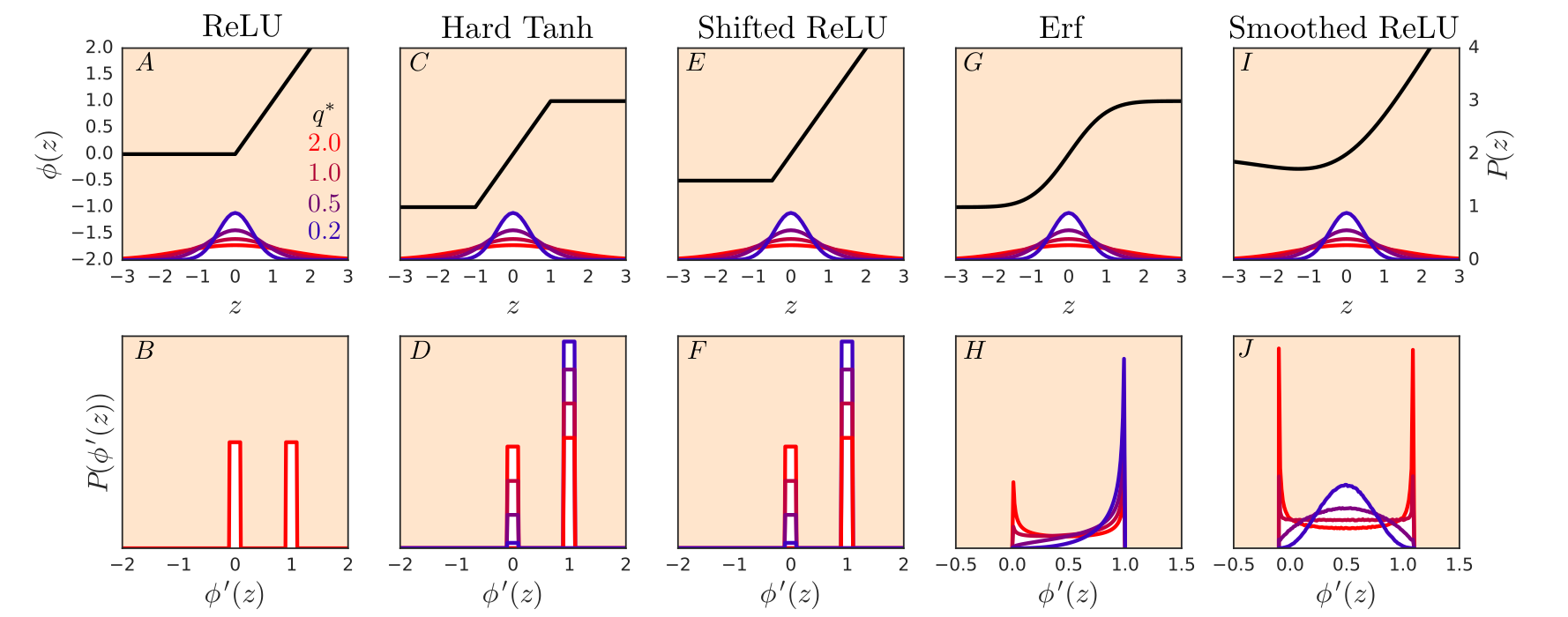 [Figure: Pennington, Schoenholz, Ganguli, AISTATS2018]
[Figure: Pennington, Schoenholz, Ganguli, AISTATS2018]
The Limit Spectral Distribution of
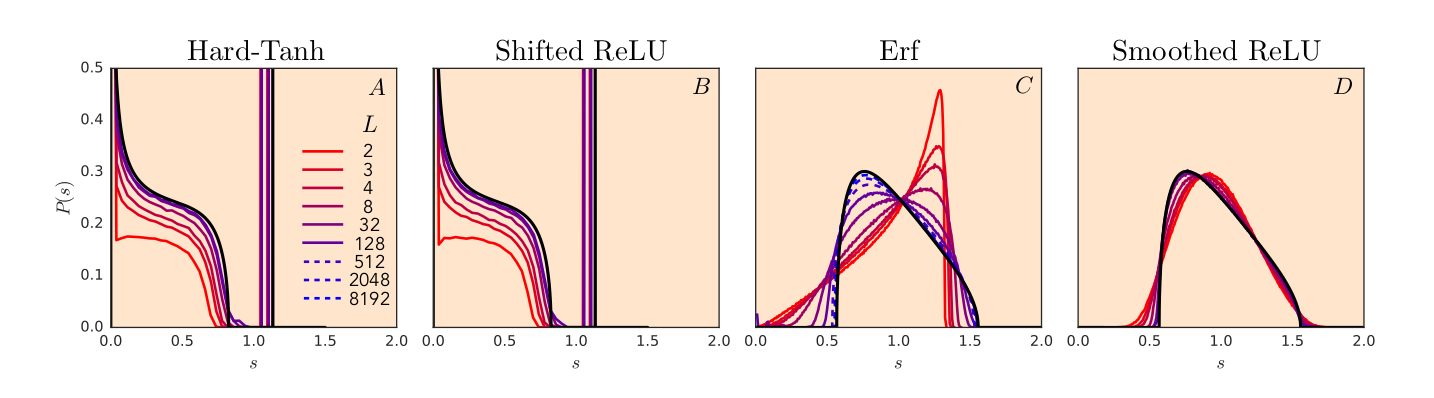 [Figure: Pennington, Schoenholz, Ganguli, AISTATS2018]
[Figure: Pennington, Schoenholz, Ganguli, AISTATS2018]
3.Neural Tangent Kernel
Neural Tangent Kernel
Under continual version of GD, learning dynamics of parameters is given by:
( * The learning rate is fixed.) Then, learning dynamics of DNN is given by:
where
**Informal[Jacot+NeurIPS2018, Lee+NeruIPS2019]**Under the wide limit , the learning dynamics of DNN are approximated by
where the neural tangent kernel is defined as
The neural Tangent Kernel is A Surrogate Model of DNN+GD
Based of NTK, we can do Bayesian estimation in the same way as NNGP. Moreover, with NTK, we can simulate the gradient descent at any step of ensemble networks.
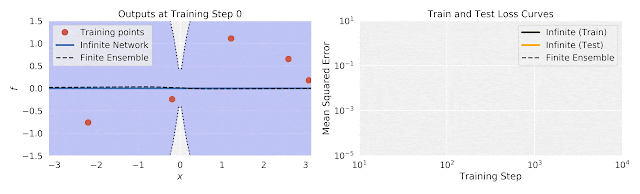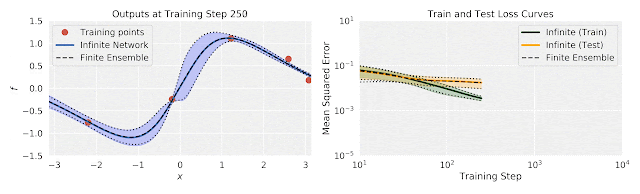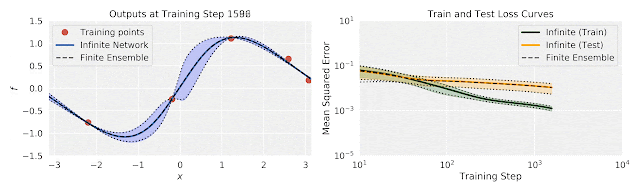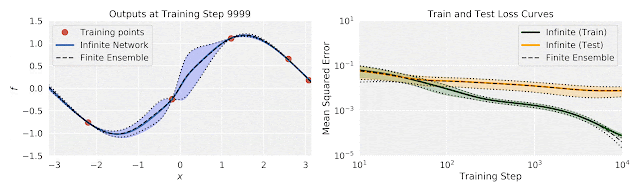 [Figure from Google “Fast and Easy Infinitely Wide Networks with Neural Tangents”]
[Figure from Google “Fast and Easy Infinitely Wide Networks with Neural Tangents”]
Appliable to CNN/ResNet
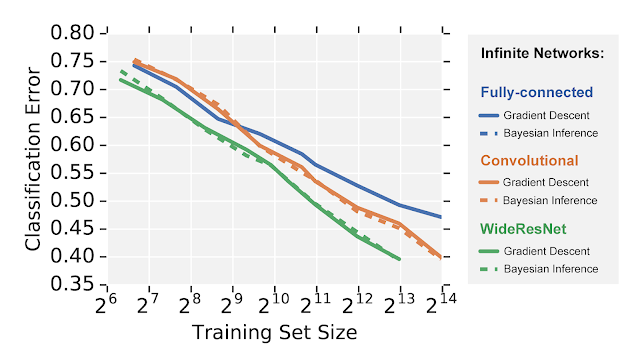 Figure from [Google “Fast and Easy Infinitely Wide Networks with Neural Tangents”]
Figure from [Google “Fast and Easy Infinitely Wide Networks with Neural Tangents”]
Moreover, NTK is appliable to Attention: Infinite attention: NNGP and NTK for deep attention networks [https://arxiv.org/abs/2006.10540\]
Eigenvalue Spectrum of NTK
“Spectra of the Conjugate Kernel and Neural Tangent Kernel for linear-width neural networks” Z. Fan & Z. Wang https://arxiv.org/abs/2005.11879 They treat the standard formulation: Gaussian Initialization x Multi-samples x Small output dimension, and they get a recurrence equation of the limit spectral distribution of NTK. Figures: Red lines are theoretical prediction
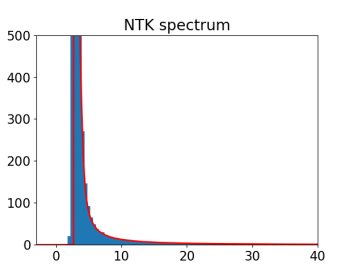
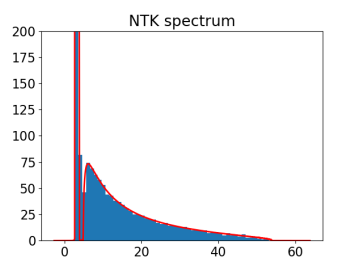
One-sample NTK
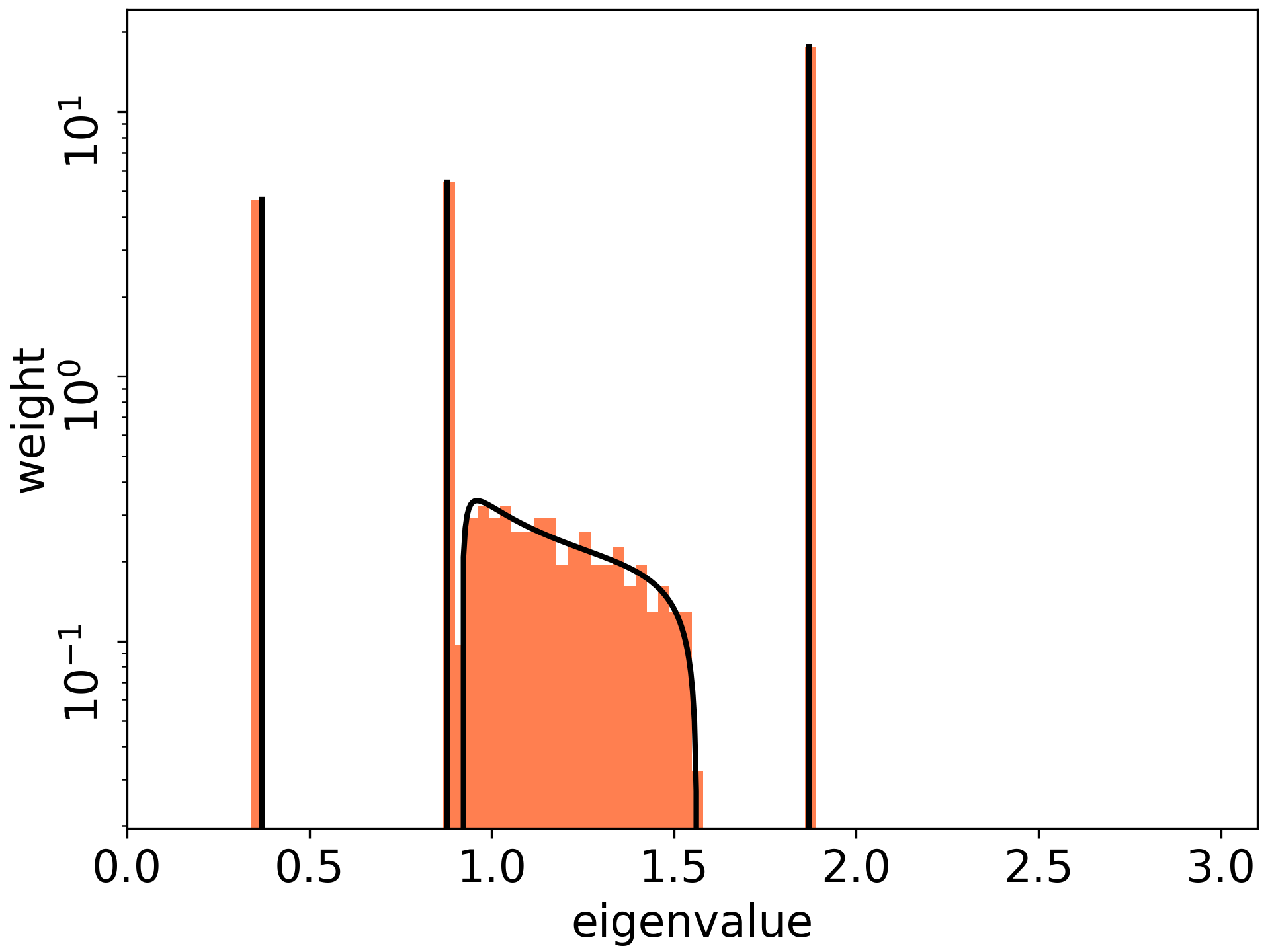
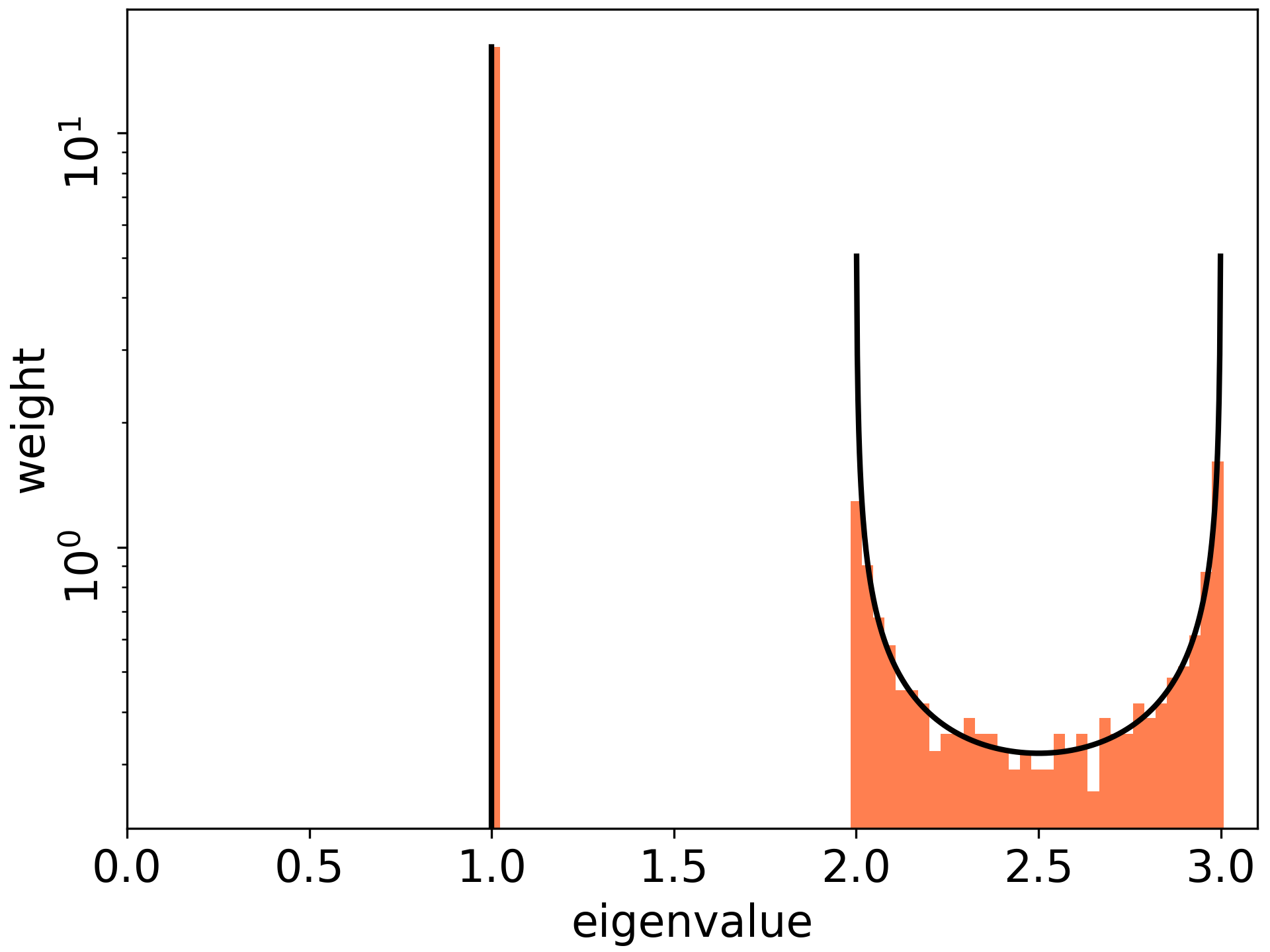
TH& R.Karakia “The Spectrum of Fisher Information of Deep Networks Achieving Dynamical Isometry” https://arxiv.org/abs/2006.07814, In AISTATS 2020. When the DNN achieves dynamical isometry, the spectrum of the (one-sample x high-dim output)” NTK” concentrates around the maximal value, and the maximal value is O(L). (Sketch)Under an assumption on Asymptotic Freeness, we have the following recursive equations:
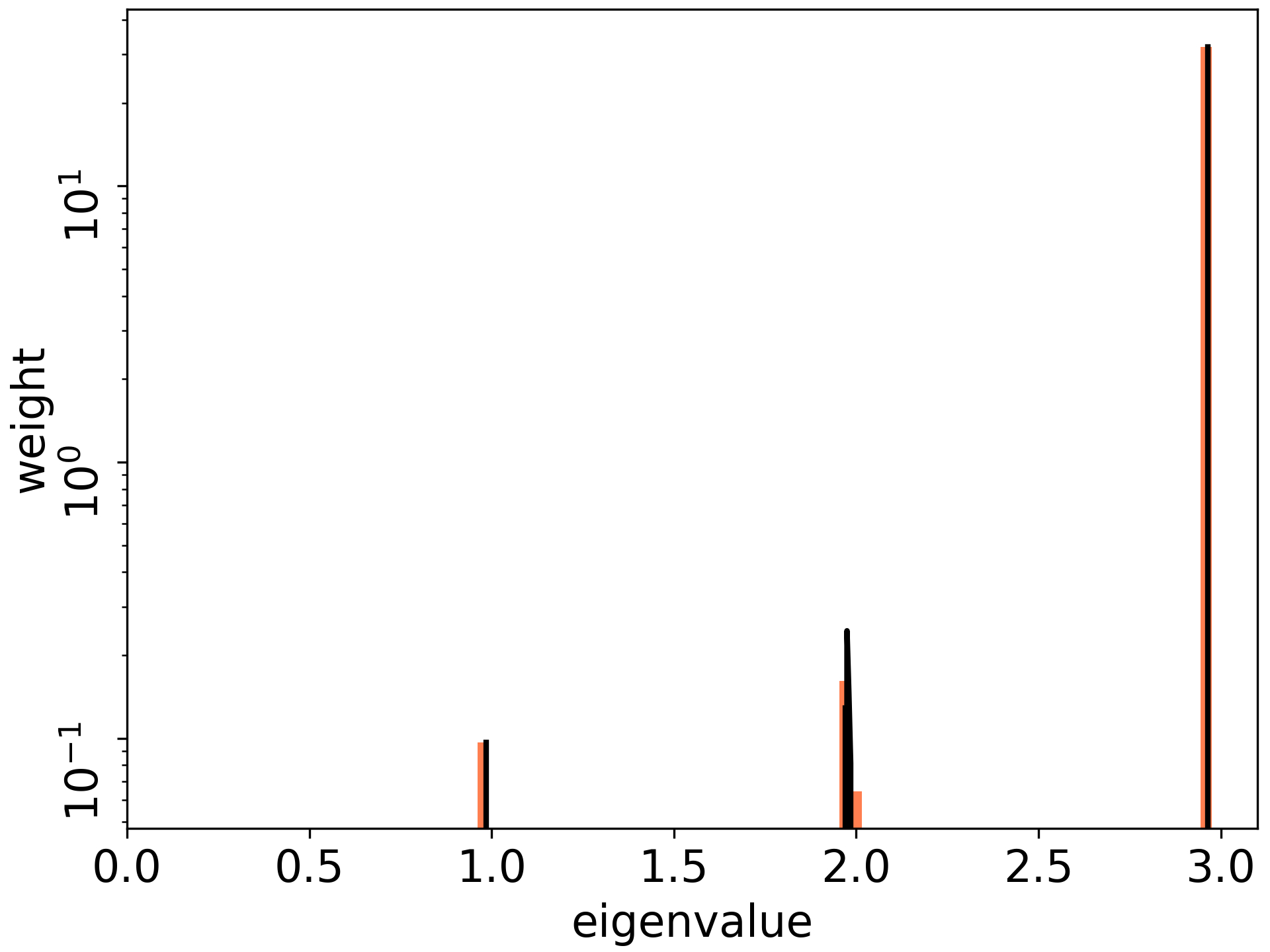
NTK & Learning Rate
The spectrum (eigenvalues) of the NTK has a vital role in tuning the learning dynamics. e.g. The learning dynamics do not converge. e.g. The conditional number detemines the converge speed.
Redline (the borderline of the exploding gradients) : This line is expected by our theory!
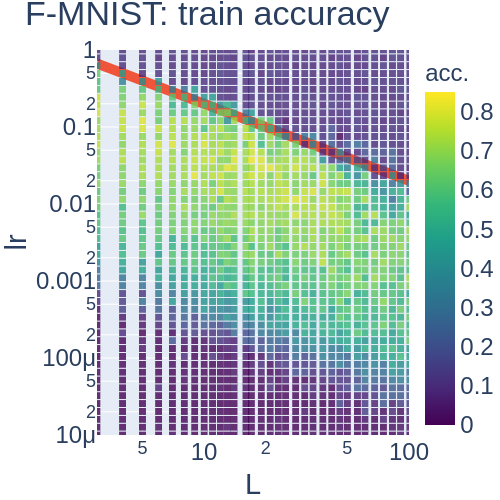
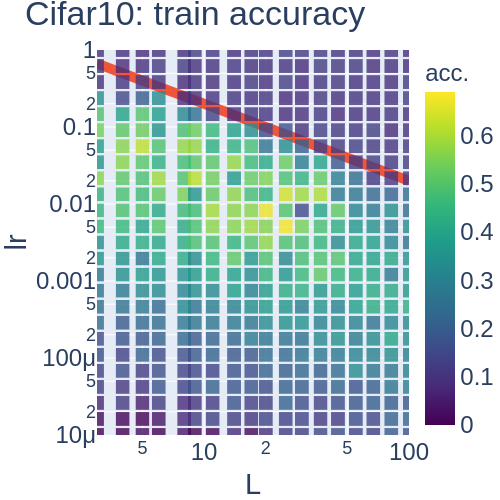
G. Yang expanded NTK to a more general one: maximal update parametrization (muP)!
4. Asymptotic Freeness
Asymptotic Freeness and Free Probability Theory
Definition(Asymtptotic freeness, C-version)[Voiculescu’85] Let be a family of random matrices and adjoints. The family is said to be asymptotically free almost surelyif there exist C-probability spaces and elements so that for any , the following holds:
where is the free product of the tracial states.
Example
For let
- be Ginibre or Haar orthogonal random matrix,
- be a constant diagonal matrix with a limit distribution as Then and are a.s. asymptotically free as N \to \infty.
Asymptotic Freeness of Jacobians
Let be weight matrices in MLP and be scaled Haar orthogonal random matrices. (The Gaussian case is treated by : [B. Hanin and M. Nica.], [L. Pastur. ], [G.Yang] ) Theorem [CH22] Assuming that have limit joint moments. Then
are asymptotically free as almost surely.
Difficulty: Entries of are not independent.
(Sketch of Proof) Invariance of MLP + Taking submatrix Construct orthogonal matrix fixing , i.e.
and
with
For Then we only need to show the asymptotic freeness of submatrices of
5. Effective Expression of MLP-Mixer
Understanding Wideness in Practical Models!
Preliminaries
MLP
MLP (multilayer-perceptron) is a composition of transforms in the form of
where is a parameter matrix ( the transforms do not share the parameter matrices).
Static Mask: Consider a matrix of entries 0 or 1 and replace W by M \odot W:
MLP-Mixer
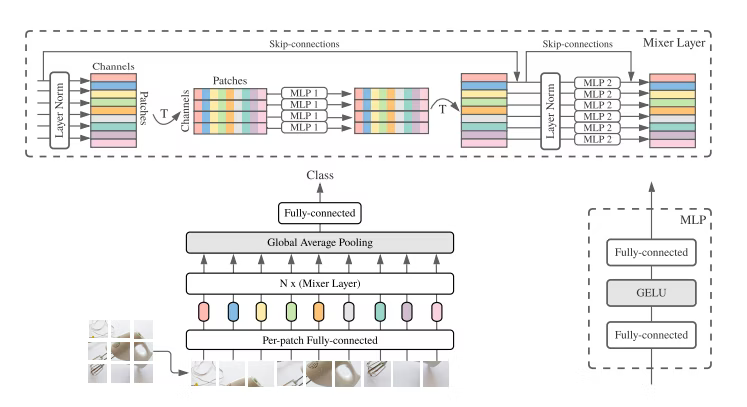 NeurIPS2021, Tolstikhin, et.al
NeurIPS2021, Tolstikhin, et.al
The structure is less structured than Convolutional Neural Networks or Vision Transformers.
Blocks of MLP-Mixer:
where , , , .
Symmirarity between MLP-Mixer and MLP via vectorization
Vectorization and effective width
We represent the vectorization operation of the matrix matrix by ; more precisely,
In other words, the map is the representation
We also define an inverse operation to recover the matrix representation.
There exists a well-known equation for the vectorization operation and the tensor ( or Kronecker) product denoted by ;
for and .
As discussed later, the aforementioned equation corresponds to the vectorization of an MLP-Mixer block with a linear activation function.
The vectorization of the feature matrix is equivalent to a fully connected layer of width
with a weight matrix . We refer to this as the *effective width *of mixing layers.
Under vectorization of feature matrices
Channel-Mixing layer is converted into :
Token-Mixing layer is converted into:
In MLP-Mixer, when we treat each feature matrix as an -dimensional vector , the right multiplication by an weight and the left weight multiplication by a weight are represented as \begin{align}
This expression clarifies that the mixing layers work as an MLP with special weight matrices with the tensor product. As usual,
Mixer is equivalent to an extremely wide MLP
Moreover, the ratio of non-zero entries in the weight matrix is and that of is .
e.g. Block-matrix rep:
Therefore, the weight of the effective MLP is highly sparse.
Commutation Matrix
Furthermore, to consider only the left multiplication of weights, we introduce commutation matrices:
A commutation matrix is defined as
where is an matrix. Note that for any entry-wise function ,
Note that
Effective Expression of MLP-Mixer: Channel-MLP Block:
Token-MLP Block:
MLP with static-mask
Static Mask: Consider a matrix of entries 0 or 1 distributed and replace W in each layer of MLP by :
- The mask matrix is fixed during the training.
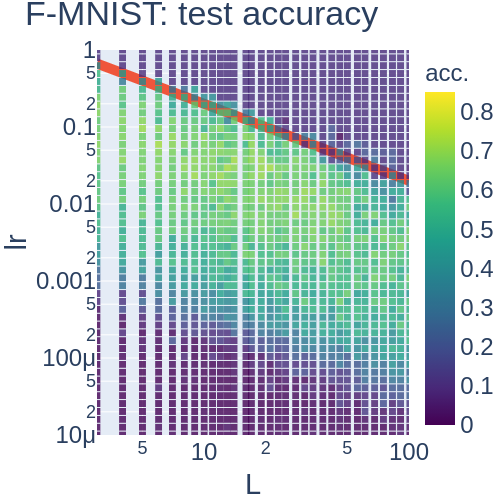
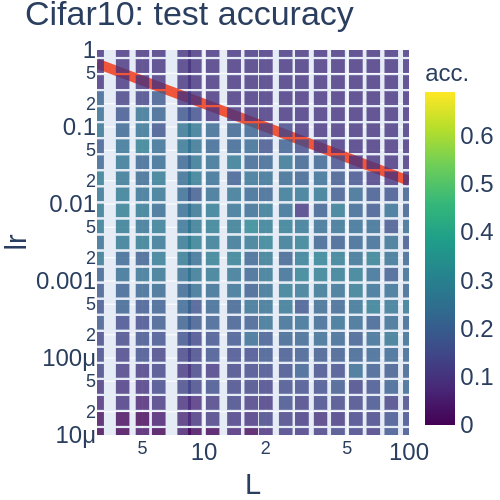
Hidden features and test accuracy
To validate the similarity of networks in a robust and scalable way, we look at the similarity of hidden features of MLPs with sparse weights and MLP-Mixers based on the centered kernel alignment (CKA) Nguyen T., Raghu M, Kornblith S.
In practice, we computed the mini-batch CKA [Section~3.1(2)](Ngueyen 2021) among features of trained networks.
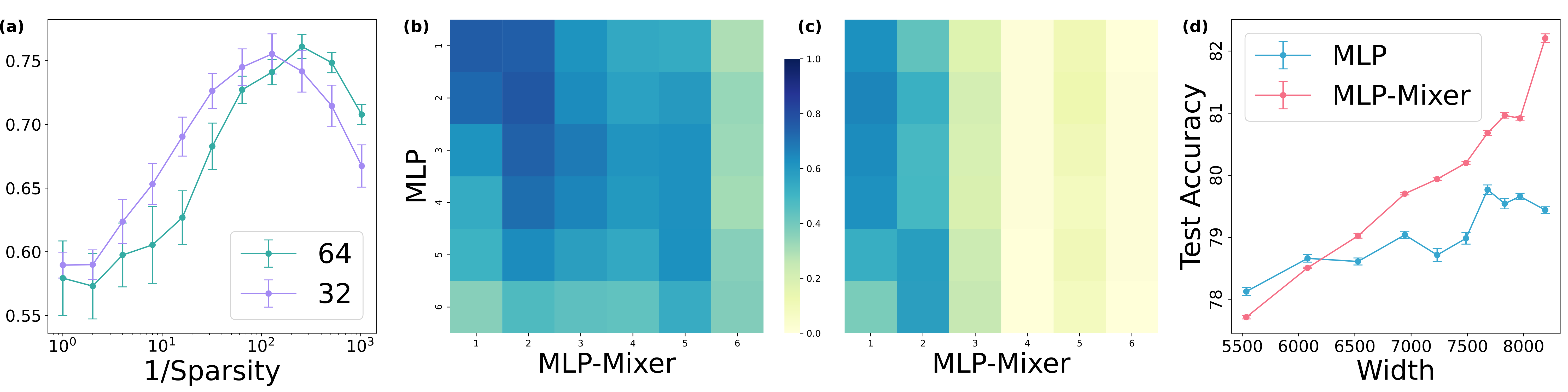
Each experiment is done on CIFAR10with four random seeds. (a) Average of diagonal entries of CKA between trained MLP-Mixer () and MLP with a static mask with different sparsity (= ratio of 1 in entries of masks). Sparser MLP was similar to (b) CKA between MLP-Mixer () and MLP with the corresponding sparsity , and (c) CKA between the Mixer and a dense MLP. (d) Test accuracy of MLPs with sparse weights and MLP-Mixers with different widths under .
6. Alternative to MLP with static masks
The comparison in larger scales
Random Permuted Mixer
Since the MLP with static mask requires much memory, comparing it with MLP-Mixer on larger images (such as ImageNet) is harder than CIFAR10.
We introduce Random-Permuted (RP) Mixer by replacingwith random permutation matrices in the following way:
where and are independent uniformly distributed permutation matrices.
Note that
- RP-Mixer is less structured than MLP-Mixer: RP-Mixer does not share tokens.
- RP-Mixer is more algebraically structured than MLP with random static masks:
Similarity of MLP-Mixer and RP-Mixer: Tendency on S and C
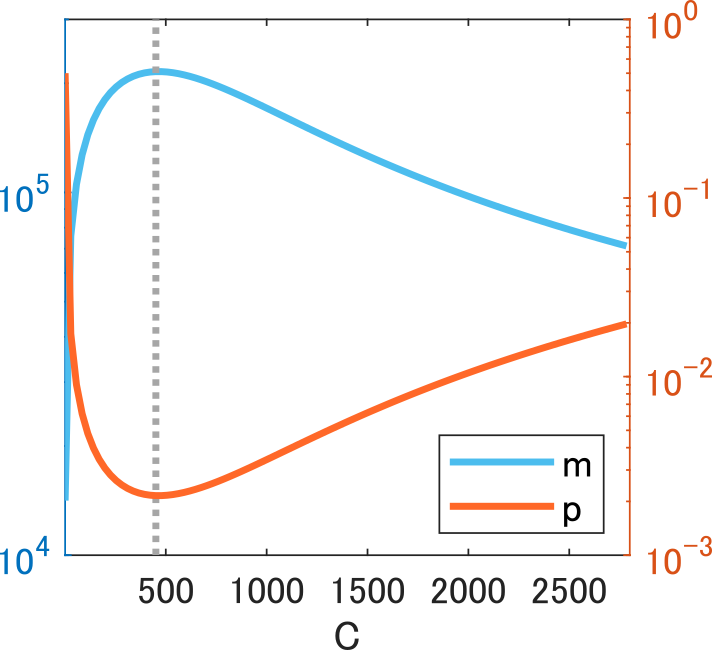
the max is achieved when with
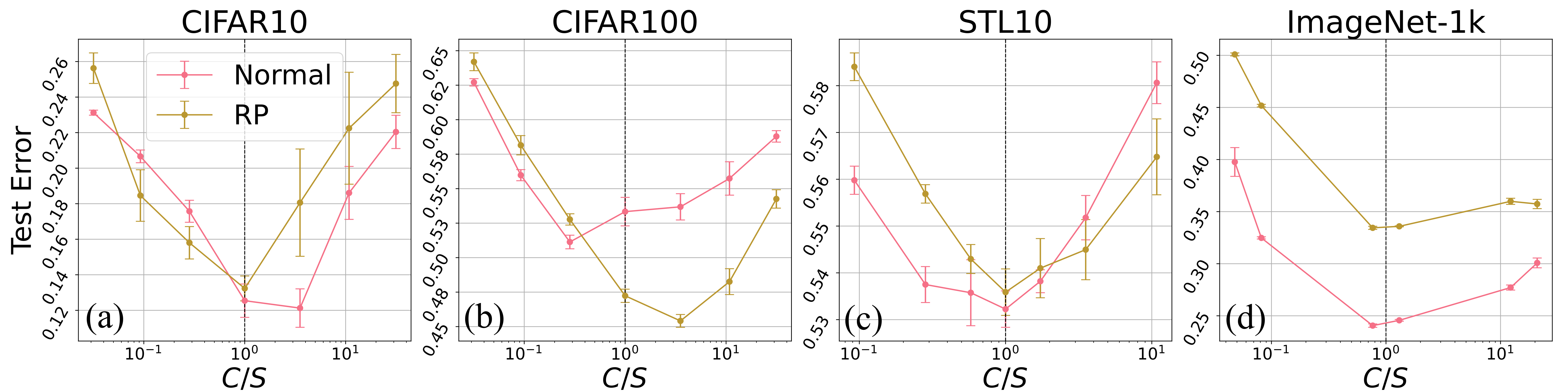 Mixers achieved highest test accuracy around C=S.
Mixers achieved highest test accuracy around C=S.
Application to HPS : An increase in the width fixed number of connections
To validate the similarity, we compare the classification error of both networks with different sparsity. Under the fixed number of connectivity, the sparsity is equivalent to the wideness.
The following hypothesis has a fundamental role:
Hypothesis(Golubeva et. al (2021)) An increase in the width while maintaining a fixed number of weight parameters improves test accuracy.
The average number of non-zero entries per layer :
By widening, the test accuracy improved. In addition,

Test Accuracy improved by choosing to widen the layers:
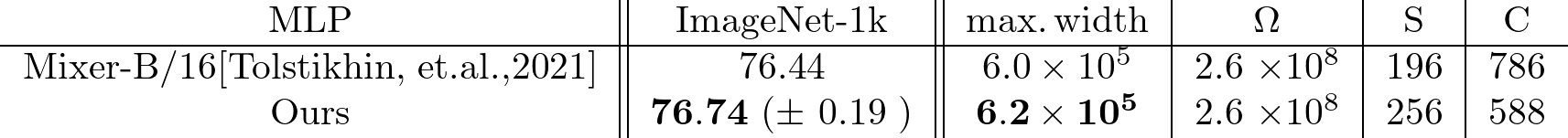
The Monarch matrix is a non-activation version.
Dao, et. al 2022 proposed a monarch matrix:
where and are the trainable block diagonal matrices, each with blocks of size . The previous work claimed that the Monarch matrix is sparse in that the number of trainable parameters is much smaller than in a dense matrix. Despite this sparsity, by replacing the dense matrix with a Monarch matrix, it was found that various architectures can achieve almost comparable performance while succeeding in shortening the training time. Furthermore, the product of a few Monarch matrices can represent many commonly used structured matrices, such as convolutions and Fourier transformations.
Summary
- Taking a wide limit gives us a theoretical understanding of MLP.
- Taking a wide limit when fixing the number of connections gives us practical knowledge of MLP-Mixer.
Future Work: Free Probability Theory has a role in the spectral analysis of deep neural networks. When does the freeness have a role in practical deep neural networks? ・・・ random but hierarchical structured features/network?